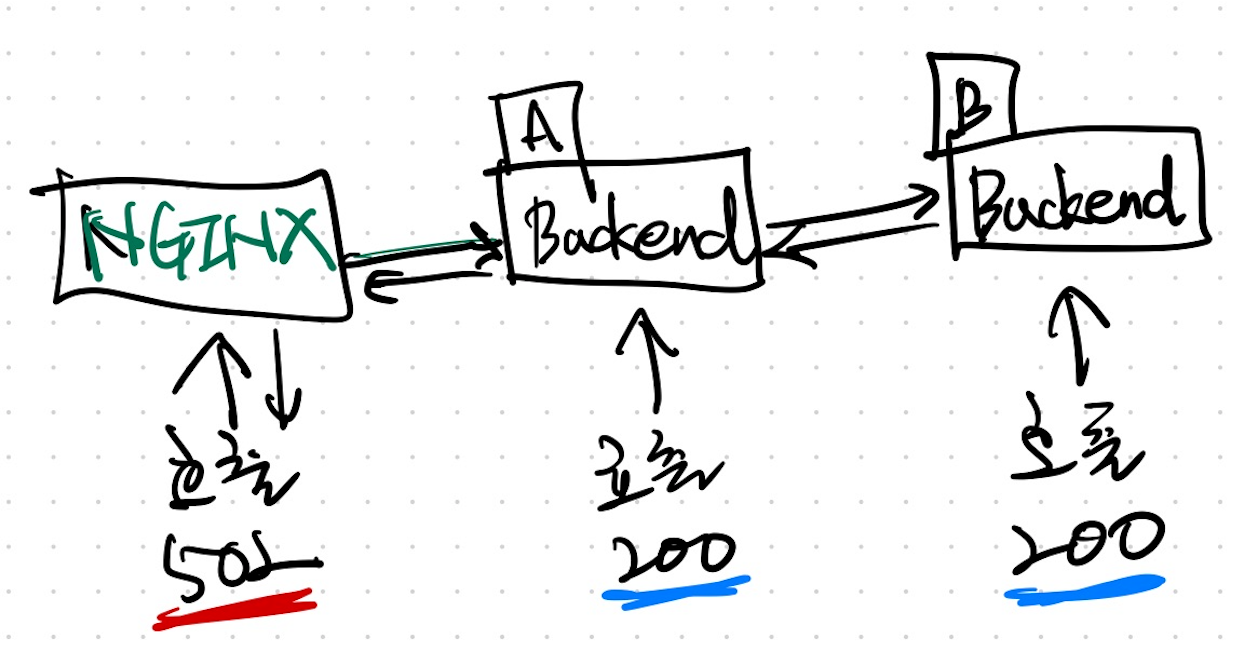
회사에서 비트버킷을 git 저장소로 활용하고 있는데, 유독 한 서비스에서 한글을 비롯한 다국어 인코딩이 깨졌다. 정확히는 모든 한글이나 일본어, 한문 등이 ???로 표기되었다. 정작 서비스는 정상적으로 동작하는데 로그상의 인코딩이 모두 깨져서 출력되었다. 하지만 소스를 수정해서 해결하기 아쉬운 부분은 원래 사용하던 비트버킷의 파이프라인으로 실행해서 배포를 하면 정상적으로 로그에서 다국어도 깨지지 않았다. 이관된 젠킨스에서 파이프라인을 실행하면 로그상의 다국어들이 모두 퀘스천마크로 깨져서 출력되었다.
요즘 모든 질문을 커서에게 던지고 있다. 물론 커서는 유료로 구독해서 사용중이다. 그냥 첨에 되어있던데로 클로드 3.5로 되어있는 커서에게 질문을 던졌는데 몇번의 시행 착오를 겪었다.
커서는 자꾸 소스를 수정해서 문제점을 해결하는 방안을 줬다. 그래서 상세하게 현재 상황을 설명하고 계속 좋은 답변이 나올 수 있도록 질문을 상세화 시켰다.
그래서 결국은 좋은 답변을 유도할 수 있게 되었는데 아쉬운점은 이미 기존에 커서가 준 답변에서 해답들을 찾을 수 있는 키워드들을 계속 커서가 말을 하고 있었다는 것. 무척 빠른 속도로 AI가 발전하고 있지만 아직도 발전할 여지들이 많아 보였다.
소스 수정없이 배포에 성공해서 한글도 안깨졌으면 좋겠다는 내 요청사항에 커서는 아래와 같은 해결방법을 제안했다. 아래 YAML을 컨테이너를 정의하는 부분의 일부다.
env:
- name: LANG
value: "C.UTF-8"
- name: LC_ALL
value: "C.UTF-8"하지만 실패,
나는 젠킨스의 파이프라인과 비트버킷의 파이프라인을 커서에게 제공했고 그 기반으로 커서가 답변하기 시작했다. 계속 실패를 하자 성공 직전에 커서는 다음과 같은 제안을 했다.
"비트버킷 파이프라인에서 실제 실행될 때의 locale 설정도 확인해볼 필요가 있을 것 같습니다. 비트버킷 파이프라인의 Build 단계에 다음 명령어를 추가해서 실행해보시겠어요?"
그래서 커서가 알려준데로 잘되는 비트버킷의 로케일을 확인했더니 미묘하게 다른 무언가가 있었다.
+ locale
LANG=en_US.UTF-8
LANGUAGE=en_US:en
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=en_US.UTF-8
어라?
같은 UTF-8인데 앞에 C가 아니다.
커서는 다른 부분을 발견했다면서 아래와 같이 설정하는것을 제안했다.
env:
- name: LANG
value: "en_US.UTF-8"
- name: LC_ALL
value: "en_US.UTF-8"
- name: LANGUAGE
value: "en_US:en"적용하고 젠킨스를 배포 했더니
정상동작!
로그에서 한글이 잘 표현되었다.
별개로 이 두개는 왜 다른건지가 궁금해서 질문을 던졌다.
답변은 아래와 같았다.
C.UTF-8과 en_US.UTF-8의 주요 차이점을 설명해드리겠습니다:
C.UTF-8:
최소한의 로케일 설정
기본적인 UTF-8 인코딩만 지원
언어 특정적인 설정이 없음
주로 컨테이너의 기본 설정으로 사용됨
2. en_US.UTF-8:
완전한 로케일 설정
UTF-8 인코딩 지원
다국어 처리를 위한 추가 설정 포함
정렬 순서, 날짜 형식 등 언어별 특성 포함
CJK(중국어, 일본어, 한국어) 문자 처리를 위한 추가 설정 포함
모르던 것을 하나 알게 되었다. 이렇게 설명을 잘해 줄 수 있으면 첨에 젠키스에서 C.UTF-8을 사용하고 있다고 나왔을때 부터 혹은 커서가 추천해줄때 처음부터 en_US.UTF-8로 해줬으면 얼마나 좋았을까? 라고 푸념을 해본다. 인간의 욕심은 끝이 없다.
결론,
젠킨스에서 실행하는 기본파드의 로케일과 gradle 파드의 로케일의 환경설정을 변경함
C.UTF-8 -> en_US.UTF-8